









June 5, 2026
Mobile App Penetration Testing: Methodology, Tools & Checklist
Mobile App Penetration Testing: Methodology, Tools & Checklist

Fiza Nadeem


Fiza Nadeem is an SEO content writer at ioSENTRIX with 2.5+ years of experience in content writing, copywriting, and SEO.
AI requires a different approach to red teaming because machine learning models introduce dynamic, non-deterministic attack surfaces that traditional security testing was not designed to evaluate.
Unlike conventional applications, AI systems can be manipulated through data inputs, model behavior, decision logic, and downstream integrations rather than static code vulnerabilities alone.
As organizations deploy AI across fraud detection, customer service, healthcare, finance, and gaming platforms, adversaries increasingly target model weaknesses such as prompt injection, data poisoning, model inversion, and unauthorized model abuse.
Red teaming for AI addresses these risks by simulating real-world adversarial behavior across the entire AI lifecycle.
AI red teaming is an adversarial testing discipline that evaluates how artificial intelligence systems behave under intentional misuse, manipulation, and attack conditions.
It extends beyond infrastructure compromise to include model behavior, decision integrity, and trustworthiness.
AI red teaming typically assesses:
Unlike traditional penetration testing, AI red teaming focuses on how systems respond, adapt, and potentially fail when confronted with malicious or unexpected inputs.
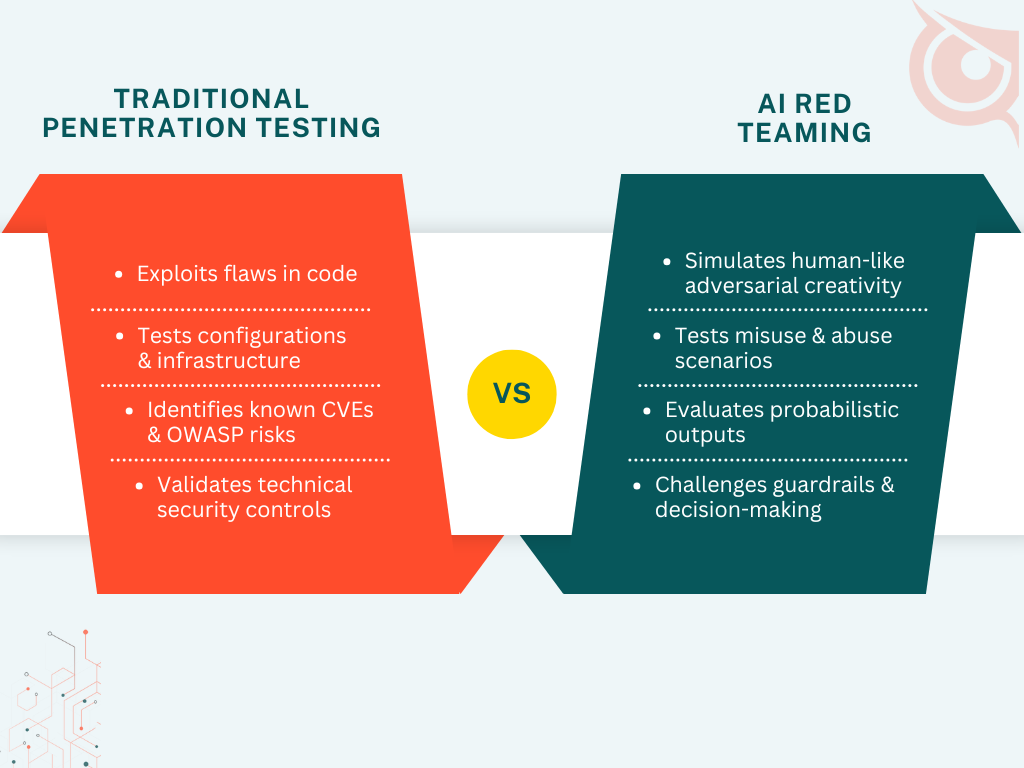
AI red teaming differs from traditional penetration testing by targeting behavioral and logical weaknesses rather than purely technical vulnerabilities.
Conventional testing identifies exploitable flaws in code, configurations, and infrastructure, while AI systems require adversarial evaluation of outcomes and decisions.
Key differences include:
AI red teaming identifies threats that are invisible to traditional testing, particularly those exploiting model behavior and data dependencies. These threats often bypass standard security controls.
Common AI-specific threats include:
According to research published by MITRE and OpenAI, prompt-based attacks against large language models have increased significantly as AI adoption accelerates, underscoring the need for adversarial testing.
Organizations should perform AI red teaming before deployment and continuously as models evolve, data changes, and threat techniques advance.
One-time assessments quickly lose effectiveness in adaptive AI environments.
Recommended triggers include:
AI red teaming supports compliance by providing evidence of proactive risk management for AI-driven systems. As regulators introduce AI-specific governance requirements, organizations must demonstrate reasonable safeguards.
AI red teaming contributes to:
This is increasingly relevant for organizations already addressing controls such as those outlined in SOC 2 penetration testing requirements.
Red teaming improves ROI by prioritizing high-impact AI risks rather than distributing resources across low-likelihood issues. Targeted adversarial testing reduces waste and improves defensive focus.
Benefits include:
This mirrors the economic advantages described in the analysis of the ROI of penetration testing and PTaaS.
Threat modeling provides the foundation for effective AI red teaming by defining likely adversaries, assets, and attack paths. Without this context, red team exercises lack strategic focus.
AI-focused threat models examine:
AI red teaming is particularly important for high-risk industries where AI-driven decisions have financial, safety, or reputational consequences. These sectors face targeted adversarial activity.
Examples include:
AI red teaming improves incident response by exposing how AI failures propagate across systems and workflows. Understanding failure modes accelerates containment and recovery.
Insights gained support:
Organizations can get started by identifying AI assets, defining threat scenarios, and engaging experienced adversarial testing teams. A structured approach ensures measurable risk reduction without disrupting innovation.
To evaluate AI risk exposure and design an adversarial testing program, schedule a consultation with ioSENTRIX.
No, AI red teaming is relevant for organizations of all sizes deploying AI in business-critical workflows.
No, AI red teaming complements penetration testing by addressing risks unique to model behavior and AI-driven logic.
AI red teaming should be conducted continuously or after significant model, data, or integration changes.
AI red teaming reduces breach likelihood by identifying misuse paths that could lead to data exposure or system abuse.





